Personalized Representation from Personalized Generation
|
* Equal contribution
|
|
† Work partially done as a student researcher at Google.
|
|
‡ Work done at Google.
|
|
§ Co-supervised, order by coin flip.
|
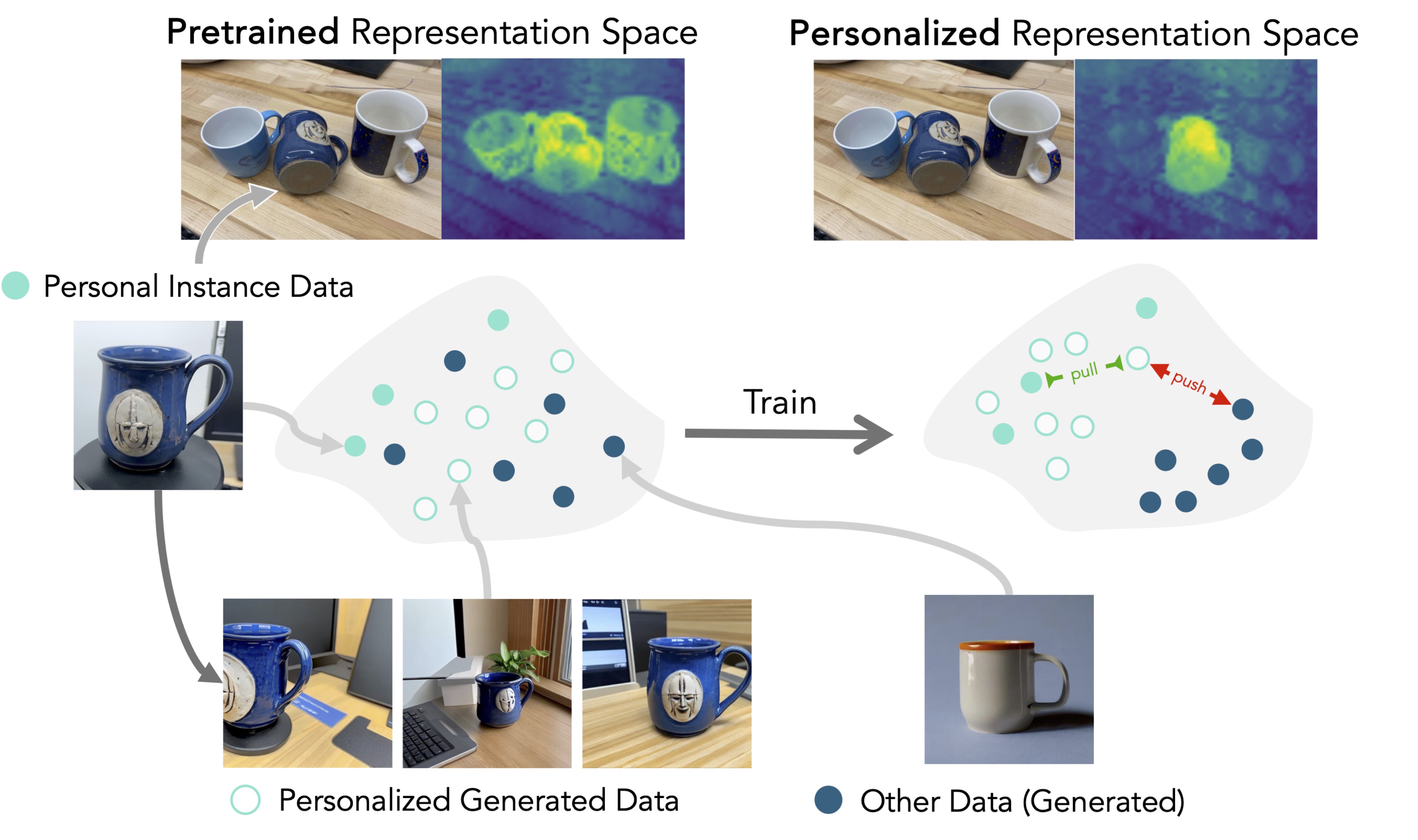
Learning personalized representations from limited real data.
We explore whether and how synthetic data can be used to train a personalized representation.
Given a few real images of an instance, we generate new images and contrastively fine-tune a general-purpose pretrained model.
This gives us a personalized representation, useful for diverse downstream tasks.
Abstract
|
Modern vision models excel at general purpose downstream tasks. It is unclear, however,
how they may be used for personalized vision tasks, which are both fine-grained and data-scarce.
Recent work has successfully applied synthetic data to general-purpose representation learning,
while advances in T2I diffusion models have enabled the generation of personalized images from just a few real examples.
Here, we explore a potential connection between these ideas, and formalize the challenge of using personalized synthetic
data to learn personalized representations, which encode knowledge about an object of interest and may be
flexibly applied to any downstream task relating to the target object. We introduce an evaluation suite for this challenge,
including reformulations of two existing datasets and a novel dataset explicitly constructed for this purpose, and propose
a contrastive learning approach that makes creative use of image generators. We show that our method improves personalized
representation learning for diverse downstream tasks, from recognition to segmentation, and analyze characteristics of image
generation approaches that are key to this gain.
|
What is a Personalized Representation?
Adapting large vision models such as CLIP, DINO, etc to personalized tasks -- which are fine-grained and data-scarce -- remains difficult.
We introduce the notion of a personalized representation: a general-purpose representation that has been specialized to a target object, separating it from all other objects, and can be flexibly applied to any downstream task. In the same way that general representations can be applied few- or zero-shot to downstream tasks, a personalized representation can be applied to classification, segmentation, etc for the particular object.
In this paper, we ask: Is it possible to learn a personalized representation from only three real images of a single object?
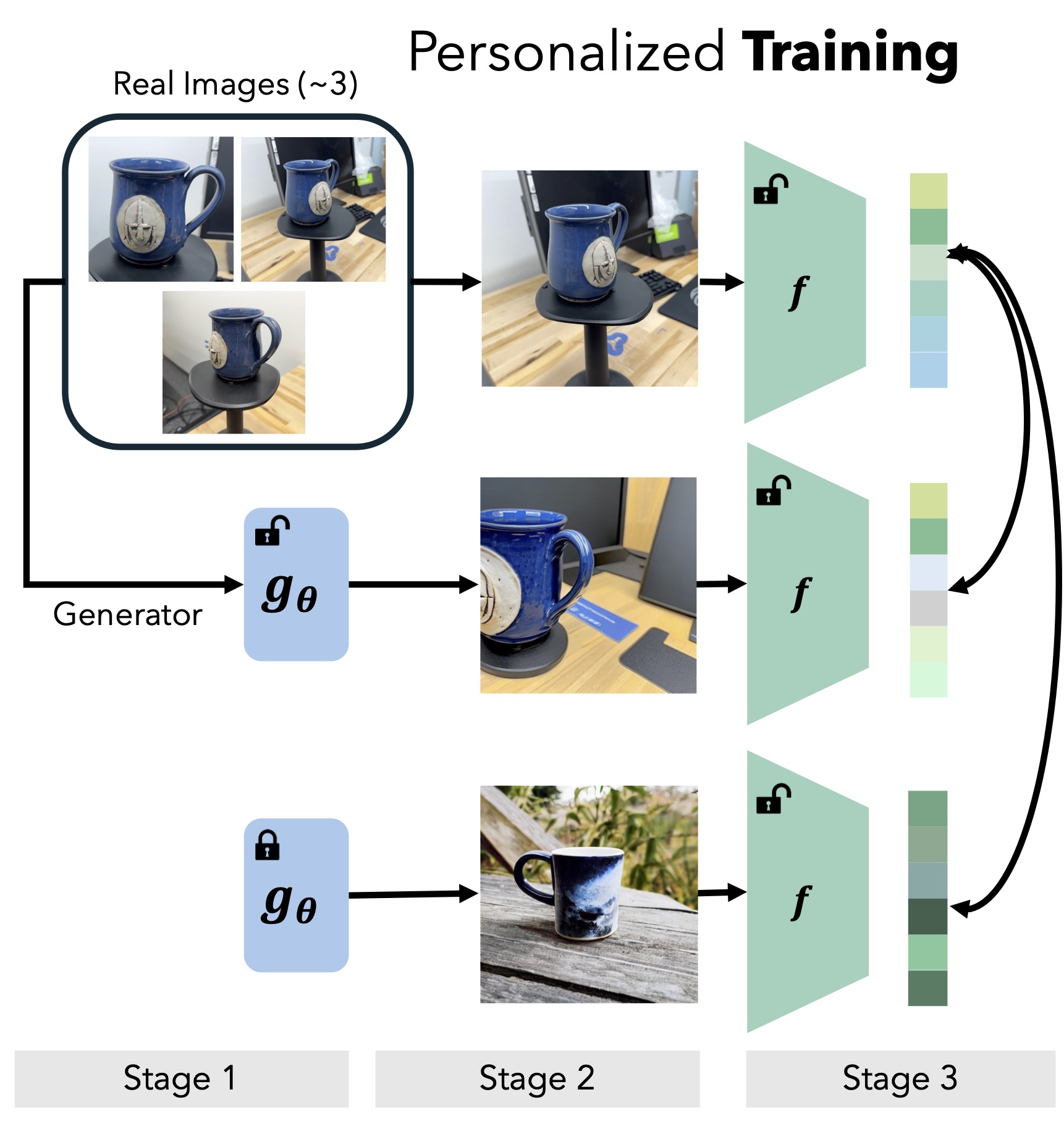
Method
We introduce a three-stage pipeline for training personalized representations:
- Prepare a personalized generator (such as DreamBooth) using the small real-image dataset.
- Generate synthetic positives (i.e. images of the target instance) and negatives (images of other objects in the same semantic category).
- Contrastively fine-tune a general-purpose model using LoRA.
We investigate different ways of generating synthetic data, including with
diffusion text-to-image models and
computationally cheaper approaches that use internet-available data.
Evaluation
We evaluate on three datasets designed to assess robustness and generalization across diverse, in-the-wild scenarios. We reformulate the DogFaceNet and DeepFashion2 datasets to evaluate representations across four downstream tasks (classification, retrieval, detection, segmentation). We also introduce the Personal Object Discrimination Suite (PODS): A new dataset for personalized vision with 100 objects and four test splits designed to test different distribution shifts.
Results
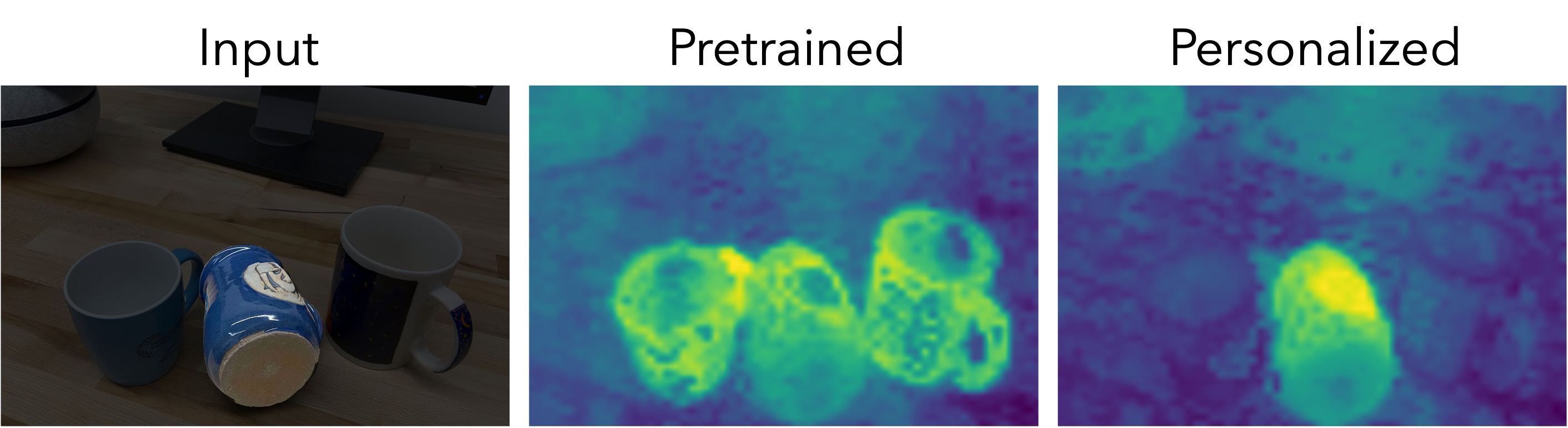
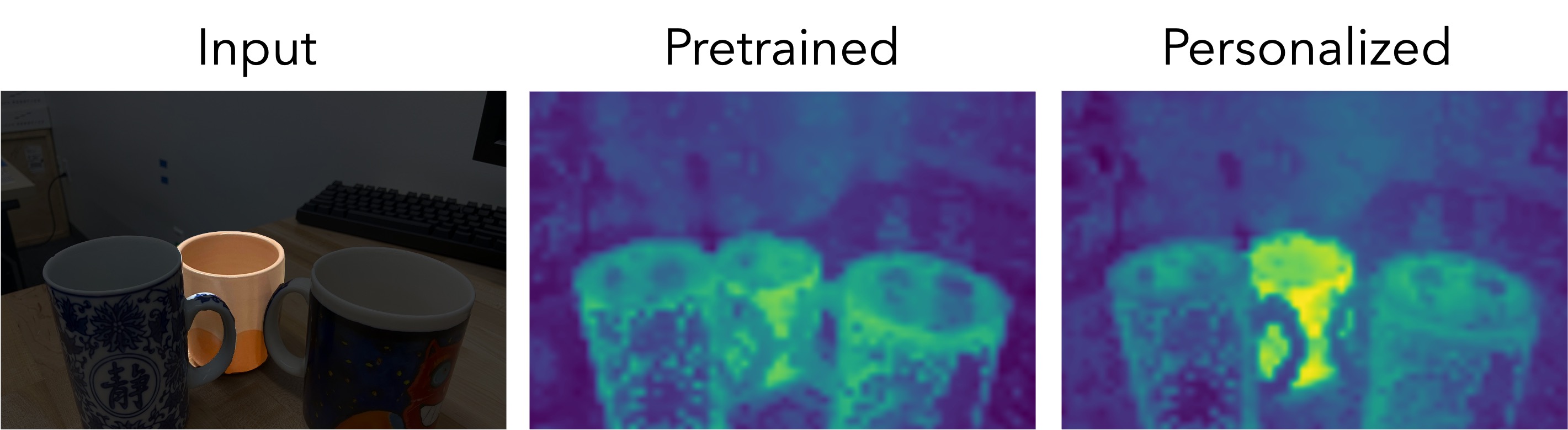
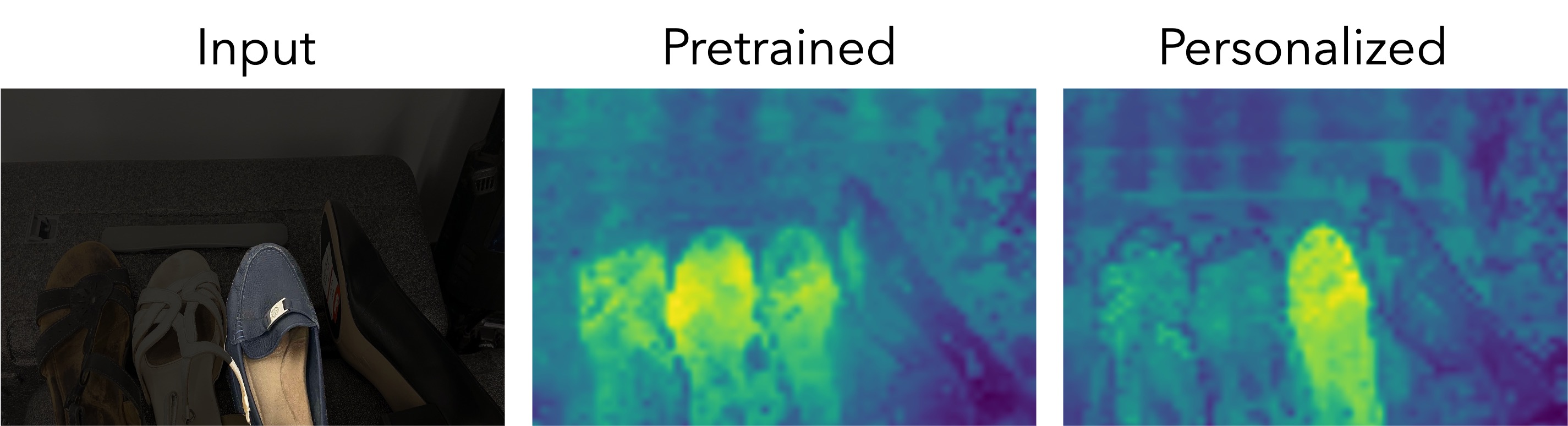
1. Qualitative Results: Dense Prediction Maps
We visualize dense prediction maps, showing the similarity of patch embeddings between test and train images. Personalized representations (right) localize the target instance better than pretrained embeddings (center), even for cases with occlusions or similar surrounding objects.
*The target object is highlighted in the test images for visualization purposes only.
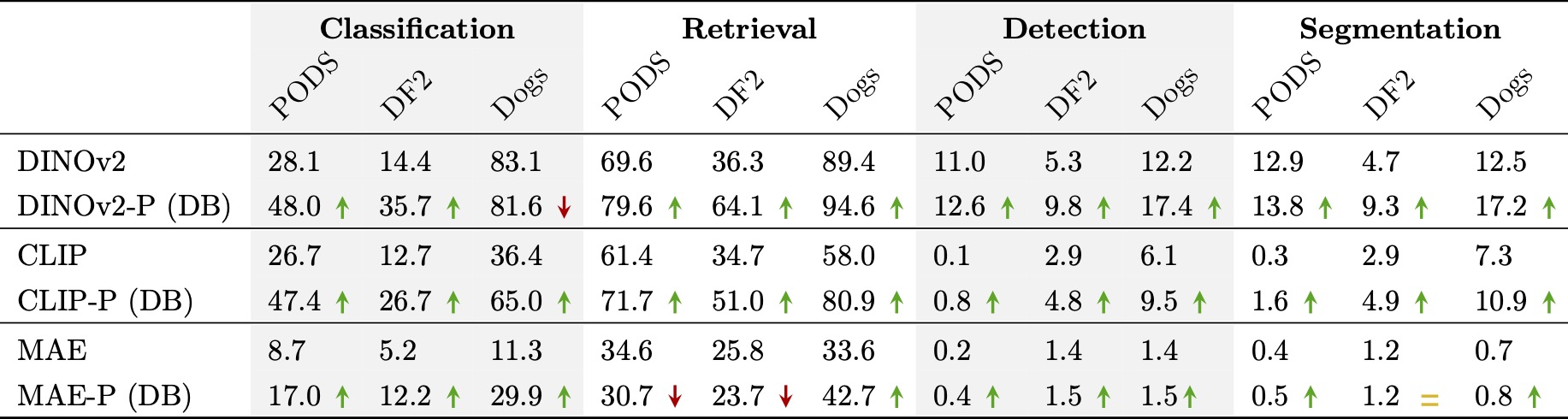
2. Personalized representations improve over pretrained representations.
For each evaluation dataset, we train personalized representations and then evaluate them directly on the four downstream tasks (without training task-specific heads). Personalized representations outperform their pretrained counterparts across datasets, backbones, and tasks (green arrows indicate better performance).
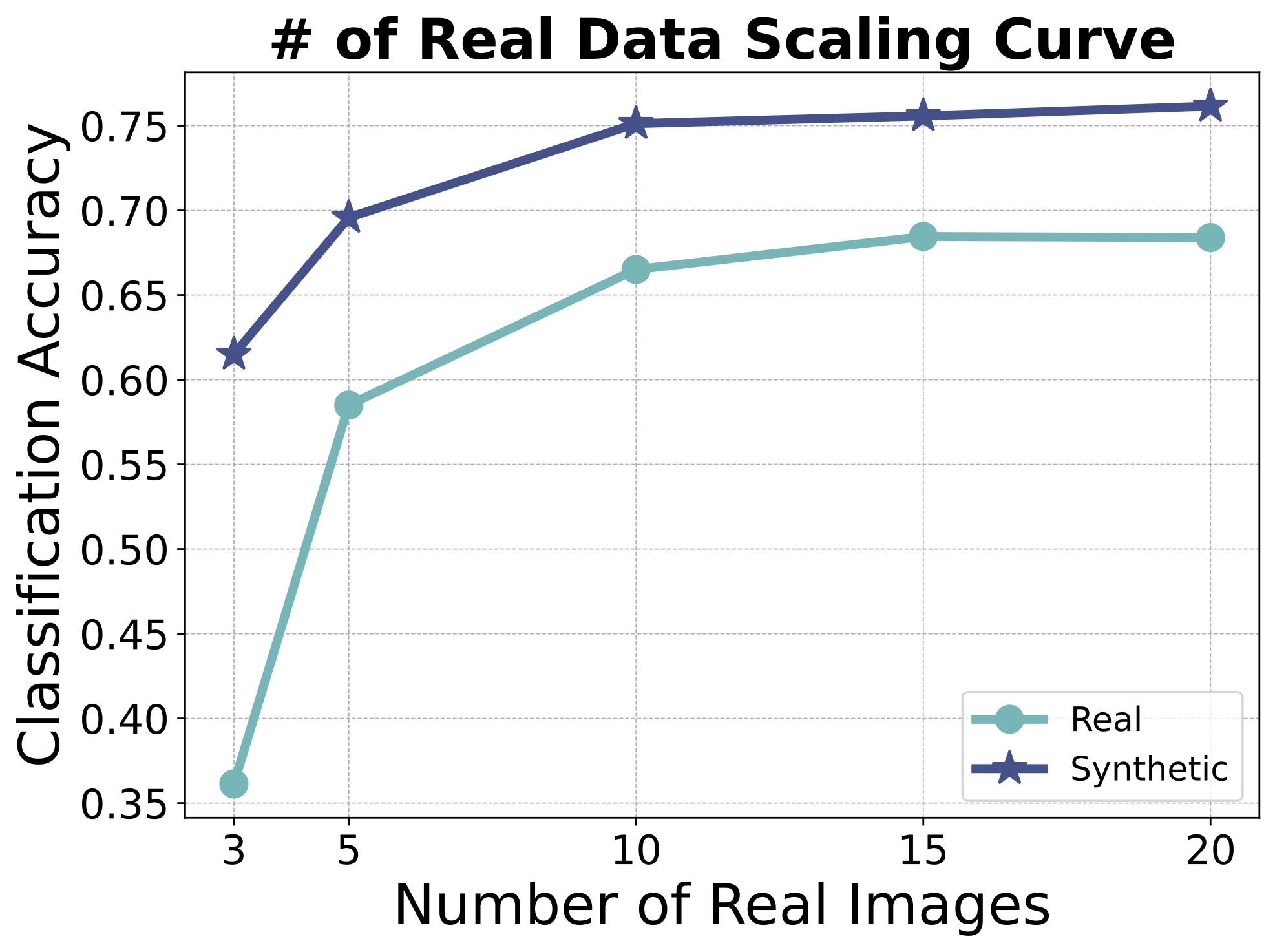
3. Synthetic data still helps at larger scales
We compare learning personalized representations from real data only and real+synthetic as the size of the real dataset scales. Synthetic data still leads to improvements, even after real-trained performance saturates.
Please refer to our paper for more results, ablations, and visualizations!
Acknowledgements
|
This material is based on work that is partially funded by an unrestricted gift from Google through the MIT-Google Program for Computing Innovation,
and by the Defence Science and Technology Agency, Singapore. This work was also supported by the AI and Biodiversity Change (ABC) Global Climate Center,
which is funded by the US National Science Foundation under Award No. 2330423 and Natural Sciences and Engineering Research Council of Canada under Award
No. 585136. S.S. is supported by an NSF GRFP fellowship. J.C. is supported by an NSERC PGS-D fellowship.
|
Bibtex
@article{sundaram2024personalized,
title={Personalized Representation from Personalized Generation},
author={Sundaram, Shobhita and Chae, Julia and Tian, Yonglong and Beery, Sara and Isola, Phillip},
journal={Arxiv},
year={2024}
}